
Research Interest
The research topics that our lab is currently focusing on are mainly (1) on-device deep learning using mobile GPUs and NPUs, (2) heterogeneous distributed deep learning on a cluster, (3) GPU frameworks for deep learning, big data processing, (4) design methodology for heterogeneous parallel platforms, and (5) algorithm/architecture co-design of ML/DL applications.
On-device LLM Inference
- LLM inference on a resource-constrained mobile GPU (like Jetson GPU)
- LLM Inference acceleration by exploiting activation sparsity
- Grasp: Group-based Prediction of Activation Sparsity for Fast LLM Inference,” Proceedings of Design Automation Conference (DAC), Jun. 2025
- SparseInfer: Training-free Prediction of Activation Sparsity for Fast LLM Inference,” Proceedings of International Conference on Design Automation and Test in Europe (DATE), Mar. 2025
- LLM fine-tuning
Distributed Heterogeneous Deep Learning
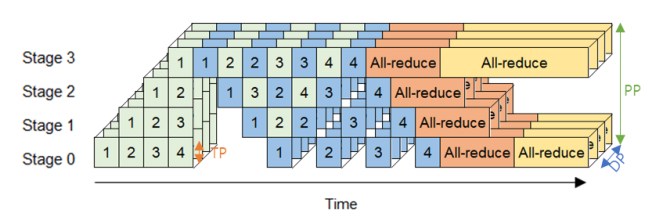
- Automated search of optimal 3D parallelization for LLM training on a heterogeneous GPU cluster; experiments across 64 GPUs
- Efficient inference for LLM
- Deep learning with heterogeneous xPUs: NVIDIA GPUs, AMD GPUs, FPGAs, and PIMs
- Funded by IITP(PI, 2025-2028, K클라우드: AI 이종 통합자원관리 기술), ETRI(PI, 2023-2025, 이기종 가속기 분산딥러닝 최적화), KEITI (Co-PI, 2021-2025, 독성예측플랫폼), and by NRF(Co-PI, 2022-2023, 슈퍼컴퓨터선도개발사업)
- FASOP: Fast yet Accurate Automated Search for Optimal Parallelization of Transformers on Heterogeneous GPU Clusters,” in the proceedings of International Symposium on High-Performance Parallel and Distributed Computing(HPDC), Jun. 2024
On-device ViT (mobile GPU, NPU)
- NAS (Neural Architecture Search) for robot vision task on mobile GPU such as Jeton GPU and NPU
- Funded by ETRI(PI, 2025 – 2026, 이기종 HW고려 로봇 비젼 신경망 자동탐색기술)
On-device/On-sensor CNN (mobile GPU, MCU)
- NAS (Neural Architecture Search) for MCU such as ARM Cortex-M CPU with 2MB flash memory
- Funded by Agency for Defense Development (ADD), PI, 2022 – 2025
- A Software Framework for Fast and Energy-efficient Inference of Sparse Neural Networks on CPU-GPU Mobile Platforms; funded by Samsung Research Funding & Incubation Center for Future Technology (SRFC), PI, 2019-2021
- “Exploiting Activation Sparsity for Fast CNN Inference on Mobile GPUs,” ACM Transactions on Embedded Computing Systems (TECS), vol. 20, no. 5s, 2021, also presented at International Conference on Hardware/Software Codesign and Software Synthesis (CODES+ISSS), Oct. 2021
- “Minimizing GPU Kernel Launch Overhead in Deep Learning Inference on Mobile GPUs,” Proceedings of the 22nd International Workshop on Mobile Computing Systems and Applications (HotMobile), 2021
- “BPNet: branch-pruned conditional neural network for systematic time-accuracy tradeoff,” Proceedings of 57th Annual Design Automation Conference (DAC), 2020
- “Towards Real-time CNN Inference from a Video Stream on a Mobile GPU (WiP Paper),” The 21st ACM SIGPLAN/SIGBED Conference on Languages, Compilers, and Tools for Embedded Systems (LCTES), 2020
- “Neural Architecture Search for Optimal Conditional Convolution Neural Networks,”, M.S. Thesis, 2021
- On-device Deep Learning Acceleration by Efficient CPU-GPU Co-execution, Quantization, and NAS; funded by Electronics and Telecommunications Research Institute (ETRI), PI, 2018-2021
- “Performance Evaluation of INT8 Quantized Inference on Mobile GPUs,” IEEE Access, vol. 9, 2021
- “Accelerating Deep Learning Inference on CPU-GPU Heterogeneous Embedded Systems,” M.S. Thesis, 2018
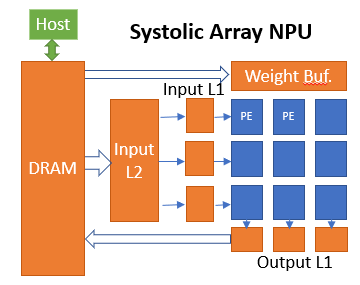
NAS for CNN Accelerator (NPU)
- Hardware Architecture Search (HAS) framework for FPGA-based CNN accelerators. With OpenCL-based HLS (High-Level Synthesis) and our sparsity-aware design space exploration framework, we aim to find (near-)optimal NPU design for various dataflow and mappings; funded by Korea Research Foundation (KRF), PI, 2022-2025
- 김수민, 안태윤, 이영민, “데이터 재사용을 지원하는 HLS 기반 효율적인 합성곱 가속기의 설계 (HLS-based Efficient CNN Accelerator Design Supporting Data Reuse),” 정보과학회논문지 제50권 제2호 pp111 – 126, Feb. 2023
- Alveo U200, Xilinx Vivado HLS v2020.1, INT8 quantized VGG16 and ResNet50
GPU Frameworks
- Deep learning and task-parallel GPU frameworks
- A GPU Programming Framework that Supports Task-parallelism and Scheduling for Deep Learning Acceleration; funded by Korea Research Foundation (KRF), PI, 2018-2021
- “GOPipe: A Granularity-Oblivious Programming Framework for Pipelined Stencil Executions on GPU,” Proceedings of the ACM International Conference on Parallel Architectures and Compilation Techniques (PACT), 2020
- “Scheduling of deep learning applications onto heterogeneous processors in an embedded device,” IEEE Access, 2020
- “HiWayLib: A Software Framework for Enabling High Performance Communications for Heterogeneous Pipeline Computations,” Proceedings of the 24th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Apr. 2019
- “VersaPipe: A Versatile Programming Framework for Pipelined Computing on GPU,” The 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO-50), 2017
- “GPU-accelerated Gradient Compression Method for Efficient Distributed Deep Learning,” M.S. Thesis, 2021
- “Understanding and bridging the gaps in current GNN performance optimizations,” Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), 2021
- GPU-enabled Big Data frameworks
- High-Performance Big Data Analytics Platform Performance Acceleration Technologies Development; funded by Institute of Information & Communications Technology Planning & Evaluation (IITP), Co-PI, 2015-2019
- Performance Enhancement of Visual Data Processing; funded by Electronics and Telecommunications Research Institute (ETRI), PI, 2014-2015
- “HybridHadoop: CPU-GPU Hybrid Scheduling in Hadoop,” HPC Asia, 2021, Cluster Computing 2023 (extended version)
- “Distributed Video Decoding on Hadoop,” IEICE Transactions on Information and Systems, 2018
- “Spark Framework Supporting Efficient GPU Executions,” M.S. Thesis, 2018
ML/DL Applications
- Power flow optimization
- Physics-Informed Neural Network (PINN) and linear solver acceleration
- Funded by NRF(Basic Research Lab), Co-PI, 2025-2028
- 4DGS (Multi-view 3D Gaussian Splatting Video) and Multi-view Light-Field Display
- Accelerating 4DGS and its mapping for Multi-view Light-Field Display;
- Funded by ETRI, PI, 2025-2026
- Light-Field
- GPU-based VoI Image Synthesis for Real-time Rendering in HMD; funded by ETRI, PI, 2019
- Video and images (faces)
- A Study on Landmark Detection in the Objects; funded by ETRI, PI, 2018
- Acceleration of Face Recognition Using WebCL on Mali GPU; funded by ETRI, PI, 2015
- Acceleration of Face Detection, Finger Tracking, and Body Tracking Using Low-Performance GPGPU; funded by LG Electronics, PI, 2014
- “Energy Efficient Real-time Face Detection on CPU-GPU Heterogeneous Embedded Platforms,” IEICE Transactions on Information and Systems, 2018
- “Real-time Face Detection in Full HD Images Exploiting both Embedded CPU and GPU,” IEEE International Conference on Multimedia and Expo (ICME), 2015
- “Real-time Integrated Face Detection and Recognition on Embedded GPGPUs,” ACM/IEEE International Symposium on Embedded Systems for Real Time Multimedia (ESTIMedia), 2014
- “Fast PCA-based Face Recognition on GPUs,” International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2013
- “An Efficient Parallelization Technique for x264 Encoder on Heterogeneous Platforms Consisting of CPUs and GPUs,” Journal of Real-Time Image Processing (JRTIP), 2014
- Natural language and text
- WiseKB: Big Data-based Self-evolving Knowledge Base and Reasoning Platform; funded by Institute of Information & Communications Technology Planning & Evaluation (IITP), 2013-2016
- “Acceleration of word2vec using GPUs,” International Conference on Neural Information Processing (ICONIP), 2016
- “Efficient Parallel CKY Parsing Using GPUs,” Journal of Logic and Computation (JLC), 2014
- Speech (old topic, before 2010)
- Please refer to the publication page
HW/SW Co-design Methodology, Performance Estimation
- Simulation and performance estimation
- “NNsim: fast performance estimation based on sampled simulation of GPGPU kernels for neural networks,” Proceedings of 55th Annual Design Automation Conference (DAC), 2018
- “Hardware-in-the-loop Simulation for CPU/GPU Heterogeneous Platforms,” ACM/IEEE Design Automation Conference (DAC), 2014